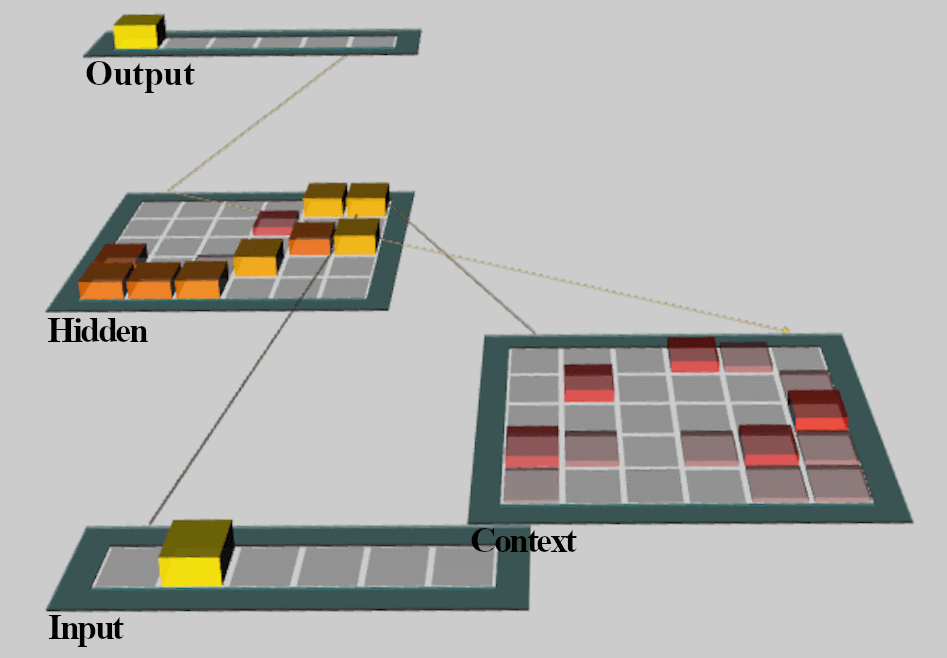
Deep learning is powerful but often a black box. To understand predictions, we need insight into what our models have learned. In this project, I examined the patterns of distributed activity in a simple Recurrent Neural Network (RNN) with a context memory layer. To simulate a toy Natural Language Processing (NLP) task, I trained my networks to “speak” with Reber grammar. This made-up grammar uses simple rules to form complex sequences and is used to study language in humans.
Since NLP tasks are naturally labeled (i.e., words or letters are the input data as well as the labels), we can use supervised classification algorithms on the corresponding activity values in the neural network and perform an error analysis. Error analysis is the systematic investigation of the mistakes in classification made by a classifier. In this context, I analyzed the activity units with error analysis in order to identify patterns of activity that appear highly similar to each other, leading to frequent classification errors, and suggesting that they share a similar internal representation. Thus, using this approach alongside the data labels, we can methodically deduce and get a glimpse into how “language” is represented in each layer.
In comparison to hierarchical clustering analysis which was inconclusive, the error analysis revealed that the representations hidden within even a simple recurrent network were abstract, with grammatical structure in the hidden layer and transition predictions in the context layer. More generally speaking, finding ways to uncover learned representations helps us build better models. However, even more importantly, making explainable AI enables everyone involved, such as stakeholders, to know the factors driving model predictions, and ultimately, key business decisions.