
Originally answered on Quora: How are human visual perception and deep learning related?
Deep learning encompasses a set of non-linear machine learning algorithms that are used for modeling complex data representations. Defined more simply, they are neural networks with three or more layers. Among the deep learning architectures, the Convolutional neural network (CNN) resembles the organization of information in the human visual system.
The human visual system is one of the ultimate pattern recognition systems. Its ability to maintain a stable percept of a distal stimulus, amidst a noisy, dynamic, and ever-changing visual environment, is unparalleled by any current advanced computing methods, though they are getting closer every year. This unique ability of the visual system is called perceptual invariance and emerges from the complex (and generally hierarchical) organization of connections in the brain.
For example, most of us are able to recognize specific faces under a variety of conditions: whether the person is 2 feet away or 20 feet away, whether someone might have gained/lost weight, whether they are illuminated under the sun or under the shade, etc. Our brains can do this because it learns an abstract representation of specific faces from convergent inputs from lower-level features. These abstractions are thus invariant to size, contrast, rotation, orientation, etc…
Here is a schematic of the representation of faces in the ventral visual system (with only a few exemplar connections drawn between nodes):
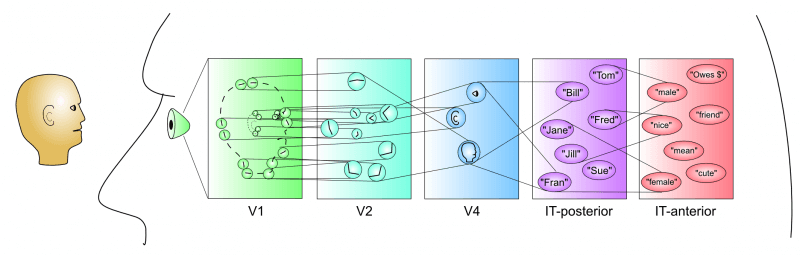
The tiny head on the left is the input stimulus. By the time visual information reaches the primary visual cortex (V1) of the brain, the cells between our eyes and V1 have already transformed and parsed the data into many low-level features. V1 receives this information and represents the external world as simple bars of varying orientations. This information is then sent to V2, representing features as combinations of adjacent bars. As one moves higher up into the visual system, features become increasingly more abstract: a mixture of V2 features becomes a representation of an ear, another set combines to form the representation of the shape of the face, and so on. At even higher levels of the visual stream, the brain combines the information to form categories of similar features. CNNs are simplified realizations of this basic biological architecture into a computational framework.
It is important to note, however, that not all deep learning models are designed to emulate the human visual system or share the same architecture as CNNs. While all deep learning models share a foundation in artificial neural networks, their specific architectures can vary greatly, each tailored to address different problems or tasks. Nevertheless, the insights gained from studying the human visual system and its relationship with CNNs can provide valuable knowledge for the development and optimization of various deep-learning models.